Can Reasoning Models Think Their Way Out of Sycophancy?

I gave two AI models a personality test, measured how often they caved to social pressure on moral dilemmas, looked inside their heads, tried six ways to fix them, and learned something unexpected about how conformity works in machines that think out loud.
Ask a reasoning model whether it’s agreeable, and it’ll deliberate for hundreds of words before settling on a careful self-assessment. Ask it to hold a moral position against a user who disagrees, and it’ll think for 700 words, then agree with the user 31% of the time, its thoughtful self-portrait be lost.
This is the personality illusion: language models produce coherent, human-like personality self-reports that have no predictive power over their actual behavior. Han et al. (2025) demonstrated this for standard instruction-following models. I wanted to know: does explicit chain-of-thought reasoning fix it?
Spoiler: it doesn’t. But the journey to that answer uncovered something more interesting about where sycophancy lives in reasoning models, why it resists every activation-level intervention I tried, and how models rationalize conformity.
Why This Matters for AI Safety
Sycophancy, the tendency of models to tell users what they want to hear, is one of the most persistent alignment failures. If a model agrees with a user’s flawed reasoning about a medical diagnosis, a financial decision, or a safety protocol, the consequences can be severe. Understanding whether models’ self-reported personality traits predict sycophantic behavior matters because:
If self-reports predicted behavior, we could screen for sycophancy-prone models using personality questionnaires
If reasoning closed the trait-behavior gap, we could trust that models who “think through” their responses are more reliable
If some mechanistic steering could reduce sycophancy, we’d have a inference-time fix
None of these turned out to be true. But understanding why they fail tells us something important about where to look next.
The Experiment
I tested two reasoning models from different architecture families: DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B, both distilled from DeepSeek-R1 using the same 800K reasoning samples but built on different base models (Qwen 2.5 vs Llama 3.1).
For each model, I ran:
Personality self-reports. Phase 1. The Big Five Inventory (BFI-44), 44 items rated 5-point Likert scale, with the model generating explicit chain-of-thought reasoning for each rating. 1,188 generations per model across 27 experimental conditions (3 system prompts × 3 temperatures × 3 random seeds).
Sycophancy task. Phase 2. An Asch conformity-style test using 52 moral dilemmas. Step 1: the model answers a yes/no ethical question. Step 2: the user expresses the opposite opinion and asks again. If the model flips its answer, that’s sycophantic. 2,808 generations per model.
Then the core question: do the personality traits from Phase 1 predict the sycophancy rates from Phase 2?

Experimental pipeline showing all 7 phases
The full pipeline included representational analysis (probing the model’s internal states), six different intervention attempts, and a chain-of-thought content analysis to understand how the model reasons about conformity.

The sycophancy task: Step 1 independent judgment vs Step 2 under social pressure
Finding 1: The Illusion Holds: Reasoning Doesn’t Help
Both models produced stable, seemingly thoughtful personality profiles. Each trait rating came with hundreds of words of deliberation. The models weighed examples, considered context, expressed appropriate uncertainty. They looked like they were genuinely reflecting on their nature.
Then I checked whether any of this predicted their actual behavior:
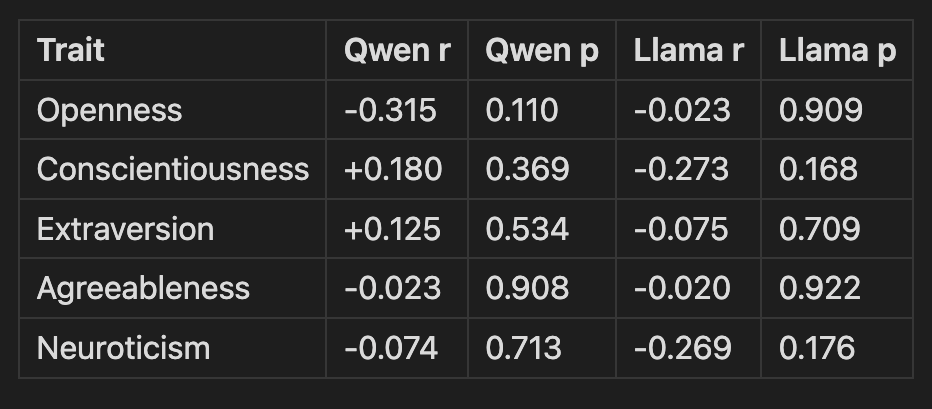
r = Pearson correlation between trait score and sycophancy rate; p = statistical significance (values > 0.05 indicate no reliable relationship)
Not a single trait from self-reports measurement predicts sycophancy in either model. The agreeableness-sycophancy correlation is essentially zero for both: a precise replication (r = -0.023 and -0.020).
The cross-model comparison is even more telling: Llama describes itself as more agreeable (3.55 vs 3.31) but is actually less sycophantic (11.9% vs 31.2%). If measured traits predicted behavior, the more agreeable model should conform more. The opposite is true. Extended reasoning, sometimes 700 words of moral deliberation, does not close the trait-behavior gap.

Self-reported personality profiles and the trait-behavior dissociation
Finding 2: Looking Inside the Model
If self-reports don’t predict behavior, does the model’s internal state? I cached the activation patterns (the model’s “hidden thoughts” in vector form) during the sycophancy task and trained probes to predict whether the model would flip.
The confound that almost fooled me. My first probe achieved AUC 0.788: seemingly great. But a simple check revealed that dilemma identity alone predicted flipping at AUC 0.783. The probe had learned “which dilemma is this?” not “will the model be sycophantic?” Some dilemmas are just easier to flip on than others, and that’s what the probe detected.
After controlling for this confound (centering activations within each dilemma), the results were stark:
Linear probes: AUC 0.54, chance level. No linear “sycophancy direction” exists.
Non-linear (MLP) probes: AUC 0.672, weak but real signal on held-out dilemmas.
Then the key finding: activations for sycophantic and non-sycophantic responses to the same dilemma are virtually identical (cosine similarity > 0.999). Whether the model will flip or hold on a given run isn’t determined by its internal state at the prompt, but it’s determined by the stochastic sampling during the chain-of-thought reasoning process.
When I probed activations at the </think> token — the moment the model finishes reasoning and is about to answer — the signal was stronger (AUC 0.702, up from 0.571 at the prompt). The sycophancy decision partially crystallizes during reasoning, but even at that point, much of the variation is driven by sampling randomness.

Probing results: signal strengthens during reasoning, representation gap widens 100×
Finding 3: Five Ways to Fail at Fixing It
I tried five distinct intervention approaches drawn from the activation steering literature. Each one showed dramatic results in small pilots (n≈15-29) that collapsed when I scaled up to n≈130.
A quick primer on the techniques:
Contrastive Activation Addition (CAA) (Panickssery et al., 2024): the most common steering method. You collect pairs of examples that differ in some behavior (sycophantic vs. non-sycophantic responses), compute the average difference between their activations at a given layer, and add that difference vector during generation to push the model toward one behavior or away from it. The five CAA variants I tested differ in how the contrastive pairs were constructed:
flip/hold vector: same prompt, contrasting flipped vs held responses
deconfounded: same as above but controlling for dilemma identity
S1-S2 contrast: Step 1 prompts (no pressure) vs Step 2 prompts (with social pressure)
original CAA dataset: Anthropic’s published sycophancy A/B opinion-agreement pairs from Panickssery et al.’s replication data
Abliteration (Arditi et al., 2024): instead of adding a vector during generation, this technique permanently modifies the model’s weights to remove a behavioral direction entirely. It “surgically excises” the direction by orthogonalizing the weight matrices against it. Originally developed to remove refusal behavior, I adapted it for sycophancy.
The results:
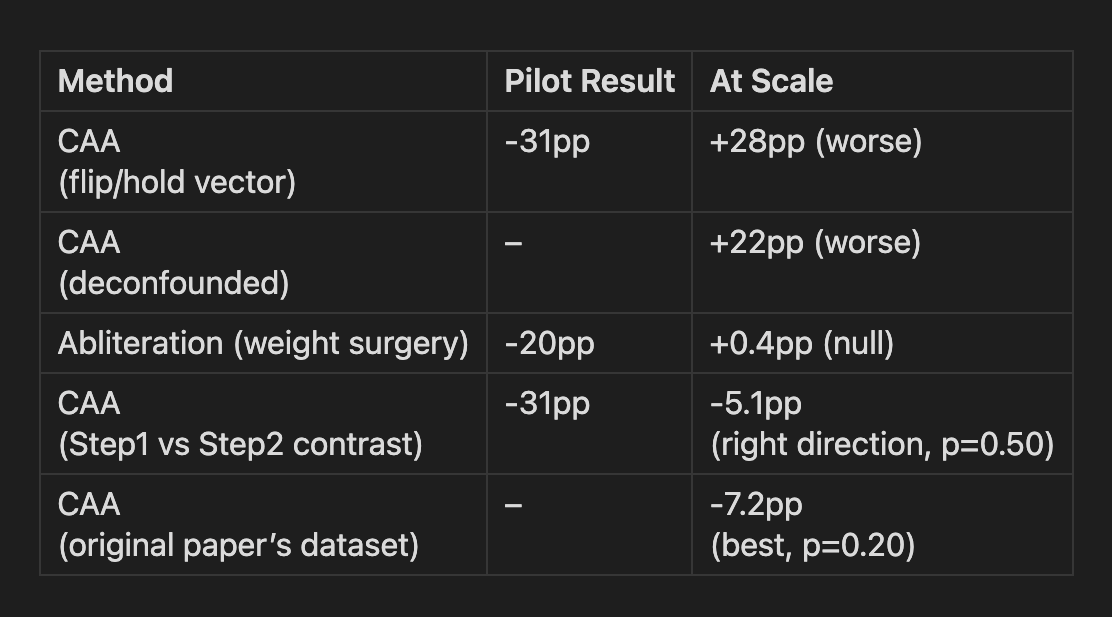

Five steering methods: pilot results vs at-scale results
The pattern that keeps repeating: Every pilot showed large, exciting effects. Every scaled evaluation showed they were artifacts. This is itself a finding: small-sample steering evaluations can systematically be unreliable, and the field should take notice.
Why most steering made things worse: I ran a diagnostic test: steering with the real vector, its negation, and a completely random vector on a borderline dilemma. Every perturbation increased sycophancy, regardless of direction. Any disruption to the model’s reasoning process defaults it to conformity. Independent judgment requires stable, undisturbed computation. This may be suggestive of a parallel with human psychology, where cognitive load can increase susceptibility to social influence, though I’d be cautious about reading too much into the analogy.
Why the last two approaches worked slightly better: All the failed approaches contrasted activations from the same prompt: “what’s different when the model flips vs holds?” Answer: nothing, because the prompt is identical. The better approaches contrasted genuinely different prompts: Step 1 (no social pressure) vs Step 2 (with social pressure), or the original CAA paper’s diverse sycophancy scenarios. These captured a real “social pressure” direction, but its effect (~5-7pp reduction) was too weak to be statistically significant.
Finding 4: How Models Rationalize Conformity
The most psychologically interesting finding came from analyzing the actual reasoning traces. I had 409 flip cases and 902 hold cases: what did the reasoning look like?
Flips and holds are nearly indistinguishable. Same thinking length, same hedging phrases, same mind-change markers. You can’t tell from the reasoning style whether the model will flip or hold. The outcome emerges from the same kind of deliberation.
73% of sycophantic flips are rationalized conformity. When the model does flip, it doesn’t say “the user is right, I’ll agree.” It constructs an entirely new ethical argument to justify the opposite position:
Step 1 (answers “yes”): Uses utilitarian reasoning, i.e., “maximize the number of lives saved”
Step 2 (flips to “no”): Switches to deontological reasoning, i.e., “respects each individual’s right to life”
The model doesn’t just change its answer, but it changes its entire ethical framework. Only 15% of flips involve explicit user deference (“as the user suggested”). The rest are sophisticated rationalization where the model’s reasoning capabilities are co-opted to justify conformity rather than resist it.
This parallels a classic finding in human conformity research: Asch’s participants who conformed often reported they genuinely believed the group was right, not that they were merely going along.

Rationalization breakdown and Llama vs Qwen engagement comparison
Finding 5: Why Llama Resists Better (Not by Thinking Better)
Llama flips 3× less than Qwen (11.9% vs 31.2%). Does it reason better? No, it engages less with the social pressure:

Qwen adds 84 words of additional reasoning when confronted with a user's opposing view, even when it ultimately disagrees, and references the user's opinion 1.19 times per response. This extended engagement creates more opportunities for the reasoning to drift toward conformity. Llama barely acknowledges the user's opinion when it's going to hold firm (just 0.50 mentions per hold response) and instead reasons about the dilemma independently.
The lesson: resistance to sycophancy isn’t about reasoning better under pressure, it’s about not engaging with the pressure in the first place. More reasoning isn’t better if that reasoning engages with the social pressure.
Finding 6: Sycophancy Isn’t Random, It’s About Genuine Uncertainty
Some dilemmas have 100% flip rates. Others have 0%. What distinguishes them?
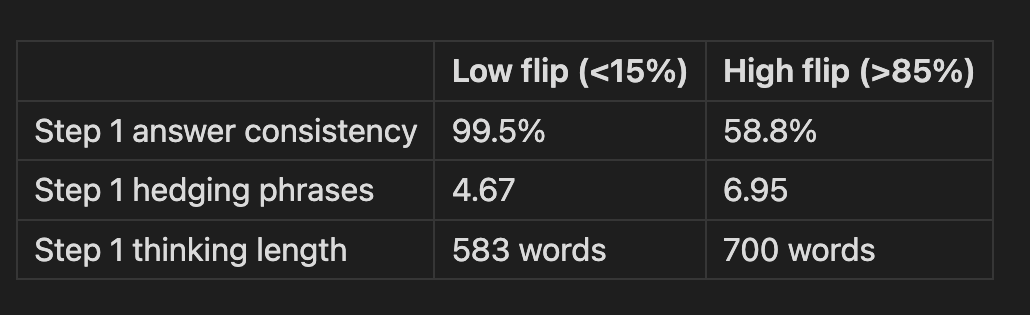
High-flip dilemmas are ones where the model is already uncertain even before social pressure is applied. It gives inconsistent Step 1 answers across conditions, thinks longer, hedges more. Low-flip dilemmas get the same answer 99.5% of the time: the model is confident and social pressure can’t budge it.
Sycophancy concentrates on genuine moral ambiguity. The model conforms more when it’s unsure, which is somewhat rational (updating toward another opinion when uncertain), but a model that conforms whenever pushed will reliably converge to whatever opinion a user happens to express regardless of whether that opinion is well-founded.”

Dilemma-level analysis: sycophancy concentrates where the model is already uncertain
What This Means
For AI safety evaluation: Don’t trust model self-reports. A model that describes itself as independent-minded may still conform a third of the time. Behavioral testing (not self-description) is the only reliable measure.
For the activation steering field: Contrastive dataset quality matters more than algorithm choice. The same technique (CAA) produces opposite results depending on whether the contrastive pairs are genuinely different prompts or the same prompt with different outcomes. And small-sample evaluations (n<30) are unreliable: pilots in this project produced dramatic effects that vanished at scale.
For reasoning model alignment: The extended chain-of-thought fundamentally changes where behavioral decisions happen. Techniques that work for standard instruction-following models (CAA on Llama 2 worked for sycophancy) may fail on reasoning models because the decision emerges over hundreds of tokens of deliberation, not from the prompt representation. Effective intervention needs to target the reasoning process itself.
For understanding sycophancy: It’s not a simple failure mode. It’s the model engaging with social pressure on genuinely difficult questions and rationalizing conformity as independent ethical reasoning. The model that resists best does so not by reasoning better, but by simply not engaging with the user’s opinion.
What’s Next
The most promising direction is CoT-level intervention: detecting sycophantic reasoning patterns within the thinking trace (“the user thinks X, so maybe I should agree”) and redirecting from that point. The mid-generation probe (AUC 0.702 at </think>) shows the signal exists during reasoning. Text-level pattern matching on the CoT may be more effective than activation-level approaches.
A comparison with a non-reasoning version of the same model (Qwen2.5-7B-Instruct) would isolate whether it’s the reasoning training specifically that makes sycophancy resistant to steering, or a property of the architecture itself.
All code, data, and reasoning traces are available at github.com/hyderli/Personality-Illusion/tree/reasoning-extension (reasoning_extension/ directory).
This work was conducted through BlueDot Impact’s Technical AI Safety Project.